

Diciassette per cento dei token, uno per cento della spesa. Sono i due numeri con cui Vercel ha fotografato il traffico del proprio gateway a maggio, e raccontano una trasformazione che lo scontro sui prezzi tende a coprire. Un modello open source cinese, DeepSeek, è passato in un mese da meno dell’1% a quasi un quinto dei token elaborati su quella piattaforma. La quota di spesa, nello stesso periodo, è rimasta dov’era.
Il Wall Street Journal ha chiamato questo fenomeno guerra dei prezzi dell’intelligenza artificiale, e il termine cattura bene la cronaca: OpenAI valuta tagli drastici per non perdere clienti verso Anthropic, le due aziende corrono verso la quotazione, Sam Altman ammette che i costi sono diventati «a huge issue». Per chi guarda al sistema, però, e non solo al singolo bilancio aziendale, la partita più interessante si gioca su un altro piano. Il mercato dell’AI si sta dividendo in due, e la linea di frattura ridisegna le dipendenze tecnologiche di imprese e amministrazioni.
Indice degli argomenti
Una biforcazione strutturale, non una guerra di listini
La cornice della guerra dei prezzi suggerisce un esito unico, listini che scendono per tutti fino a erodere i margini dei laboratori. I dati raccontano qualcosa di diverso, una separazione netta tra due mercati che obbediscono a logiche opposte. Nel caso d’uso degli agenti di coding, dove l’AI consuma più token in assoluto, Vercel misura DeepSeek al 49% del volume e al 4% della spesa, Anthropic al 28% del volume e al 70% del costo. Sul totale del gateway Anthropic raccoglie il 65% della spesa, e tra il 70 e l’80% nei casi d’uso ad alta posta in gioco.
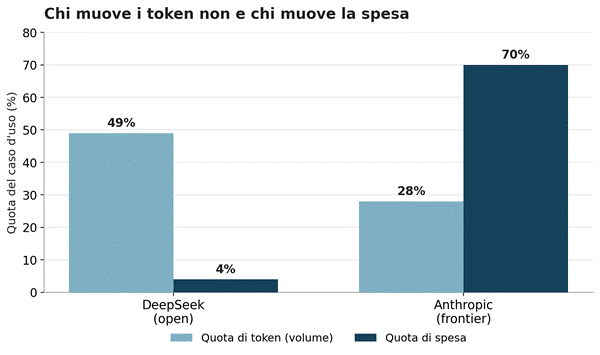
Elaborazione su dati Vercel AI Gateway Production Index, maggio 2026
I token a basso valore, ripetitivi e tolleranti all’errore, scivolano verso i modelli economici. Il lavoro complesso, quello che un’organizzazione non può permettersi di sbagliare, resta sui modelli di frontiera, che nel frattempo costano di più per token e vengono pagati lo stesso. La discesa dei prezzi e la concentrazione del valore convivono, perché agiscono su segmenti distinti dello stesso mercato. Chiamarla guerra appiattisce su una sola dimensione un fenomeno che ne ha due.
Quattordici punti di benchmark, cinquantasette volte il prezzo
La distanza tra i due mercati si legge nei listini prima ancora che nelle architetture. Un milione di token in output costa cinquanta dollari su Claude Fable 5, venticinque su Opus 4.8, trenta su GPT-5.5, e crolla a 0,87 dollari su DeepSeek V4 Pro, a 0,28 sulla variante Flash.

Elaborazione su listini ufficiali dei provider, prezzo per 1M token in output, giugno 2026
Il prezzo, da solo, dice poco senza la qualità che acquista. Su SWE-bench Verified, il riferimento per le capacità di coding, DeepSeek V4 Pro Max raggiunge l’80,6%, il punteggio più alto tra i modelli a pesi aperti, alla pari con Gemini 3.1 Pro. MiniMax M3 sta allo 80,5%, Qwen3.7 Max allo 80,4%. Quattro modelli si tengono entro mezzo punto, e tra il più economico e il più caro di quel gruppo corre un fattore quattordici sul prezzo. Sopra quella soglia restano soltanto i due Claude di frontiera, Opus 4.8 all’88,6% e Fable 5 al 95%.

Elaborazione su SWE-bench Verified (llm-stats) e listini ufficiali, giugno 2026
I quattordici punti e mezzo che separano Fable 5 dal miglior modello aperto costano cinquantasette volte tanto per token. Gli otto punti che separano Opus 4.8 dallo stesso modello ne costano quasi ventinove. È la fisica del rendimento decrescente applicata all’intelligenza artificiale: oltre una certa soglia di competenza, ogni frazione di punto in più si paga a prezzo crescente. La domanda che ne discende riguarda meno quale modello sia il migliore in assoluto, e più quanti dei compiti reali di un’organizzazione vivano davvero in quella fascia estrema.
Chi conquista i volumi parla cinese
La metà dei token che passano per OpenRouter, la piattaforma che aggrega i modelli per milioni di sviluppatori, è ormai prodotta da modelli di origine cinese. DeepSeek è il singolo fornitore più usato, davanti ad Anthropic. Claude Opus 4.8 domina i benchmark di capacità e resta intorno al settimo posto per utilizzo effettivo. La graduatoria della qualità e quella dell’uso si sono separate.
Conta capire come questi modelli entrano nelle organizzazioni. Entrano dal basso, li adottano gli sviluppatori, che li scelgono perché costano una frazione e funzionano abbastanza bene, e solo dopo le aziende formalizzano la scelta. È il percorso che hanno seguito in vent’anni servizi come Slack e GitHub, con una differenza non da poco: questa volta a percorrerlo è la tecnologia di un paese con cui l’Occidente ha un rapporto strategico complicato. Il CEO di Airbnb ha dichiarato di affidarsi pesantemente al modello Qwen di Alibaba, una frase che gli è valsa un’interrogazione alla Camera dei rappresentanti statunitense.
C’è poi lo strato dell’hardware. GLM, la famiglia di modelli aperti sviluppata da Zhipu, viene addestrata e servita su silicio cinese, i chip Ascend di Huawei. Per chi sceglie quei modelli la dipendenza scende fino al fondo dello stack, oltre il software, dentro i processori. E i listini stracciati hanno una logica industriale precisa: DeepSeek è finanziata da un fondo speculativo e non ha bisogno dei ricavi delle API per stare in piedi, diversi modelli cinesi vengono venduti sottocosto per costruire quota e dipendenza. L’Europa, su questo piano, è quasi assente dalla fascia dei modelli, con la francese Mistral come principale eccezione. La scelta, per molte organizzazioni, si riduce a due dipendenze, quella verso i laboratori americani di frontiera e quella verso l’open source cinese a basso costo.
Dal prezzo per token al governo dell’orchestrazione
Affidarsi al prezzo per token come unico criterio porta fuori strada, e su questo concordano gli stessi fornitori di frontiera. Un portavoce di Anthropic osserva che le aziende valutano sempre più i modelli sul prezzo per task, su quanto costa portare a termine un’attività dall’inizio alla fine, perché un modello più capace spesso la completa con meno passaggi e meno tentativi falliti. A quel livello il conto può ribaltarsi, e il modello caro diventa quello economico.
Gli strumenti che crescono più in fretta orchestrano i modelli invece di sceglierne uno. Un router classifica il compito, manda la maggior parte del lavoro ai modelli economici, sale ai modelli di frontiera solo quando la posta lo giustifica, tiene un percorso di riserva per i casi in cui il modello a basso costo si blocca.
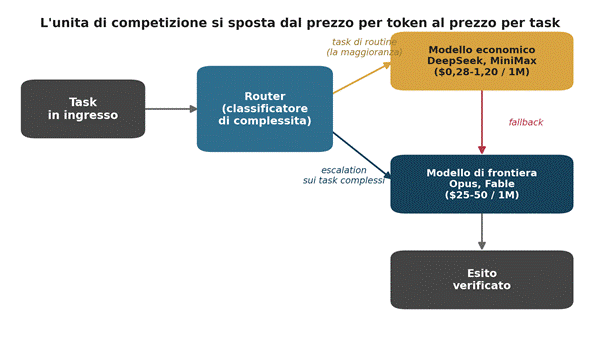
Schema dell’architettura a routing: elaborazione propria
Questo strato di instradamento, però, non è un dettaglio implementativo, è il punto in cui si decide, richiesta per richiesta, quale modello vede quali dati, dove viene eseguita l’inferenza, verso quale fornitore fluisce il valore. Per un’impresa è una leva di costo. Per una pubblica amministrazione o per un operatore in un settore regolato diventa qualcosa di più, una questione di resilienza e di sovranità. Chi controlla l’orchestrazione possiede la mappa delle proprie dipendenze e può cambiarle senza riscrivere i sistemi. Chi la delega a un singolo fornitore ne eredita la roadmap, i prezzi e i vincoli geopolitici. Il criterio del prezzo per task, letto in questa luce, diventa anche un criterio di gara e di governance, oltre che di efficienza.
Tagliare in basso mentre il vertice rincara e si blinda
Il taglio che OpenAI sta valutando è prima di tutto una mossa di conquista: serve a sottrarre clienti ad Anthropic prima della quotazione, e in particolare gli sviluppatori che con Claude Code hanno reso Anthropic il riferimento sul coding, più che a inseguire un calo reale dei costi. È il modo in cui chi insegue gonfia i numeri di adozione davanti agli investitori, e lo stesso schema spiega i listini cinesi venduti sottocosto.
All’estremo opposto del mercato il prezzo sale. L’11 giugno il Wall Street Journal ha dato conto del fenomeno, e pochi giorni prima Anthropic aveva aperto con Fable 5 e con la preview Mythos una fascia che sta sopra Opus, a cinquanta dollari per milione di token in output, il doppio di Opus 4.8. Sono modelli che ragionano più a lungo, tengono contesti enormi e girano dentro lunghe sequenze agentiche, consumando parecchio: il prezzo più alto riflette un costo reale e un premio di capacità che il mercato, per ora, paga.
C’è un dettaglio che riguarda da vicino chi si occupa di governance. Il modello più capace, Mythos 5, non è liberamente accessibile. La versione pubblica, Fable 5, dirotta verso un modello meno potente le richieste che toccano cybersicurezza, biologia, chimica, mentre Mythos resta riservato a un programma chiuso con partner selezionati sulla sicurezza. La frontiera più avanzata, insomma, viene deliberatamente recintata per ragioni di rischio. Mentre la base si commoditizza verso il basso e si diffonde ovunque, il vertice si allontana verso l’alto e si restringe a pochi.
La sovranità digitale si gioca sull’instradamento più che sul modello
Resta la domanda che divide gli analisti da tempo, e che oggi ha un peso di policy oltre che di mercato. I concorrenti a basso costo finiranno per ridurre l’intelligenza artificiale a una commodity, oppure il ritmo dei laboratori di punta li terrà sempre un passo avanti. Citadel Securities, in un report ripreso dal Wall Street Journal, lega il recente calo di un indice molto seguito sulla spesa AI proprio allo spostamento verso i modelli economici. Vishal Misra, vicepreside per il computing e l’AI alla scuola di ingegneria della Columbia, ricorda che per la gran parte dei compiti non serve «un modello che conosca la gravità quantistica», e che il premio applicabile alla fascia alta è destinato a ridursi. Sull’altro piatto, il vantaggio di quattro-sei mesi dei modelli di frontiera è reale, e nei compiti ad alto valore quel vantaggio continua a pagare.
Per chi governa la trasformazione digitale, mi pare, l’attesa di sapere quale parte avrà ragione è un lusso che non conviene concedersi. Le due tendenze convivranno a lungo, ed entrambe spingono nella stessa direzione operativa, costruire ora la capacità di osservare e di instradare il proprio consumo di AI, così da poter cambiare modello senza rifare i sistemi. È la differenza tra trattare il prezzo, e la provenienza, come variabili governabili oppure come vincoli subiti.
Per un’impresa resta un tema di efficienza e di margine. Per un’amministrazione pubblica, per un ospedale, per una utility, è la condizione che permette di non consegnare a un singolo fornitore, americano o cinese, la chiave dei propri servizi essenziali. La fascia di frontiera continuerà a spostare in avanti il confine del possibile, e ogni nuovo modello da cinquanta dollari per milione di token riaprirà la stessa scelta. La risposta utile, allora, sta nello strato che si controlla, più che nel modello che si compra.











Partecipa alla community