

Google ha rilasciato la nuova generazione di modelli open weight Gemma 4, si tratta di modelli molto capaci e, in alcune versioni che accettano input multimodale (sia immagini che audio).
Quello che colpisce di questi nuovi modelli sono le notevoli capacità a parità di numero di parametri rispetto a modelli di generazioni precedenti.
In realtà si tratta di un trend che ricercatori cinesi hanno analizzato in un recente articolo pubblicato su “Nature machine intelligence” in cui da un’analisi di oltre 50 LLM emerge un trend che indica che la “densità di intelligenza” dei modelli raddoppia ogni circa 3,5 mesi; in altre parole, ogni 3-4 mesi servono la metà dei parametri a parità di capacità del modello (portando a circa un fattore 20 di miglioramento negli ultimi due anni). Ecco quindi che un modello con “soli” 31 miliardi di parametri è capace di prestazioni che solo pochi mesi fa richiedevano il doppio o il quadruplo dei parametri e di conseguenza enormi quantità di RAM GPU per poterli eseguire. È quindi naturale chiedersi: è possibile finalmente pensare di eseguire modelli LLM che siano efficaci ed utili anche su workstation e laptop?
Ho cercato di dare risposta a queste domande provando due varianti di Gemma 4 sul mio laptop ARM (Snapdragon X Elite con NPU e GPU Qualcomm) con 32GB di RAM. Certo, si tratta di un portatile di fascia alta, ma è comunque un portatile e senza una GPU nVidia e rappresenta quindi un test interessante per capire come l’esecuzione di questi modelli sia oggi pensabile anche su sistemi decisamente piccoli su cui era sostanzialmente impensabile pensare di eseguire modelli di questo calibro solo pochi mesi fa.
Indice degli argomenti
I modelli Gemma 4
La scheda su ollama.com dei modelli fornisce molte informazioni sul loro comportamento e sulle proprie capacità. Google individua i modelli da 31B e da 26B come modelli workstation e i modelli e2B e e4B come modelli “edge”, ovvero disegnati per eseguire su dispositivi più piccoli di una workstation.

Ma cosa vuol dire la “e” in e4B? Contrariamente a quanto suggerirebbe l’intuizione la “e” non sta per “edge” ma per “effective” 4B: Google ci informa che il modello si comporta computazionalmente come un modello denso che usa 4 miliardi di parametri ma di fatto ne ha di più. Si tratta di un cambiamento di nomenclatura interessante: si passa da indicare quanti parametri ha un modello a quanti ne vengono attivati per l’inferenza. Da un confronto con altri modelli presenti sul mio sistema si può pensare che il modello abbia circa 15B parametri secondo l’architettura Mixture of Experts (MoE) con quattro esperti da 4B di parametri ciascuno. In sostanza: il modello richiede comunque una certa quantità di memoria per poter essere caricato ma computazionalmente costa poco grazie all’architettura MoE, la stessa che usa il modello da 26B (anche in questo caso con esperti da 4B).

In accordo ai benchmark i nuovi modelli Gemma funzionano decisamente meglio della generazione precedente, e i modelli edge sono i primi a supportare anche l’audio come input. Sicuramente il benchmark MMLU Pro indica una buona capacità dei modelli di trattare lingue differenti, un’informazione utile se si pensa di utilizzare il modello con l’italiano. In ogni caso i numeri sono decisamente migliori dei modelli precedenti, anche se la versione 20B di GPT-oss sembra ancora performare meglio, soprattutto del modello e4B, anche se manca del supporto all’analisi di immagini e file audio.

Esecuzione di Gemma 4 in locale sul laptop
Sono riuscito ad lanciare sul mio laptop tutti i modelli ad eccezione del più grande: il 31B richiede troppa memoria e comunque è un modello denso che non fa uso di MoE, e quindi anche dal punto di vista computazionale sarebbe troppo oneroso.
I modelli fanno uso di ragionamento, quindi la velocità di risposta del modello non è immediata, ma in generale i risultati sono più affidabili dei modelli che non fanno uso del ragionamento.
Sul mio laptop entrambi i modelli provati funzionano ragionevolmente bene e consentono di ottenere un buon token rate (se si considera anche l’output del ragionamento), e sono modelli che sicuramente possono governare agenti OpenClaw o supportare lo sviluppo di codice.
Una prova che mi ha colpito è quella del modello e4B con l’audio: non sono molti i modelli disponibili capaci di elaborare anche input audio, e gemma 4 sembra funzionare anche su audio in italiano. Ho provato a registrare un audio in cui dicevo “Quanto fa sette per quarantadue” e passarlo come input in formato wav.
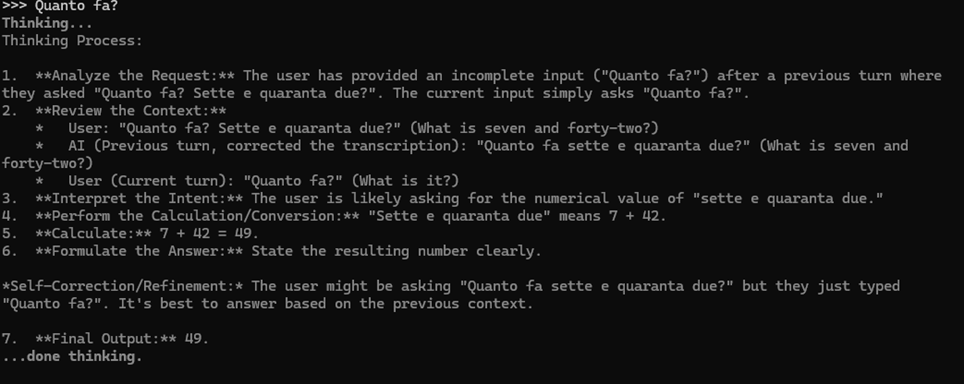
È interessante osservare come il modello tratti l’input come un’immagine ma trascriva quasi correttamente il testo (la parola “per” è divenuta un “e”). Ho quindi chiesto di fatto di effettuare il calcolo così come il modello ha trascritto ed ho ottenuto un ragionamento corretto ma con una risposta errata a causa dell’errore di trascrizione.
Quando ho puntualizzato la richiesta indicando che intendevo moltiplicazione e non addizione il modello imposta ed esegue correttamente il calcolo.
I due modelli provati vengono eseguiti in CPU (contrariamente ad altri che sul mio portatile riescono ad usare anche la NPU) ma con prestazioni decisamente accettabili che aprono possibili usi di modelli di AI generativa in locale.
Gemma 4 sul pc personale: un bilancio
Il continuo incrementare della densità di intelligenza nei nuovi modelli sta rendendo sempre più “intelligenti” modelli che sono capaci di eseguire su un laptop. Diventa sempre più facile quindi disegnare soluzioni che elaborino dati localmente senza dover trasferire dati in cloud per ottenere risultati affidabili. Il token rate di questi nuovi modelli non è ancora tale da consentire una vera e propria interazione in chat, ma sono assolutamente adatti a supportare processi di natura AI agentica che coinvolga anche la generazione di codice. È quindi arrivato il momento in cui per la valutazione dei modelli da impiegare su uno specifico progetto si debba prendere in considerazione anche se sa possibile eseguirlo localmente.
Il supporto all’input audio apre nuove possibilità sull’edge, aprendo all’elaborazione di input multimodali anche se, dalle prove effettuate gli errori di trascrizione sono ancora da non sottovalutare. Se la legge empirica sulla densità di intelligenza dei modelli che raddoppia ogni 3-4 mesi dovesse proseguire è lecito attendersi una AI più distribuita e meno centralizzata rispetto a quando i primi quasi tre anni ci hanno abituato a considerare.












