

Negli ultimi anni gli Open Government Data (OGD) hanno assunto un importante ruolo nelle strategie di trasformazione digitale delle amministrazioni pubbliche, affermandosi come una tecnologia essenziale per promuovere trasparenza, partecipazione civica, innovazione nei servizi e sviluppo economico (Kassen, 2019).
Indice degli argomenti
L’ecosistema OGD in Lombardia: un’analisi
In Italia, la Lombardia rappresenta uno dei contesti più dinamici e virtuosi a livello nazionale in questo ambito per quanto riguarda l’organizzazione e gestione degli OGD (Maretti et al., 2021): la varietà degli enti coinvolti, la presenza di ecosistemi territoriali avanzati e un crescente interesse da parte di imprese, ricercatori e società civile delineano un panorama particolarmente ricco, ma anche complesso da interpretare.
L’articolo mira a offrire una panoramica sistematica dell’ecosistema OGD in Lombardia, concentrandosi in particolare sull’evoluzione dei dataset pubblicati negli anni. Per farlo utilizziamo come fonte principale il catalogo regionale degli open data, che raccoglie oltre 5.000 risorse e costituisce la base informativa più ampia e consolidata attualmente disponibile. Pur riconoscendo che tale archivio non comprende necessariamente la totalità dei dataset prodotti sul territorio – poiché alcuni enti locali operano su piattaforme autonome o non aggiornano sistematicamente il catalogo regionale – esso rappresenta certamente un osservatorio privilegiato per comprendere le dinamiche di pubblicazione, i tipi di dataset più ricorrenti e l’articolazione degli attori coinvolti.
L’obiettivo non è soltanto descrivere “quanto” è stato pubblicato, ma mettere in luce come l’ecosistema lombardo si sia evoluto nel tempo, quali traiettorie tematiche emergono, quali enti si mostrano più attivi, e in che modo qualità, aggiornamento e granularità dei dataset contribuiscano (o talvolta ostacolino) il riuso. L’analisi vuole, dunque, a fornire una base solida per valutare lo stato attuale degli OGD in Lombardia e individuare opportunità di rafforzamento, sia sul fronte tecnologico sia su quello organizzativo e collaborativo.
Nota metodologica
L’analisi si basa principalmente su tecniche di statistica descrittiva applicate al dataset estratto dal portale Open Data della Regione Lombardia (https://www.dati.lombardia.it/), che raccoglie oltre 5.000 risorse pubblicate da enti regionali e locali. Da una parte l’obiettivo è stato ricostruire l’evoluzione temporale della pubblicazione dei dataset, e dall’altro lato, descrivere la struttura complessiva dell’ecosistema OGD lombardo, individuando pattern ricorrenti rispetto a temi, formati, enti pubblicatori e frequenza di aggiornamento.
Il dataset è stato importato e trattato in RStudio, utilizzando procedure di pulizia e normalizzazione dei metadati.
L’analisi ha fatto ricorso principalmente a: conteggi e distribuzioni di frequenza (per temi, enti, anni, formati, licenze); serie temporali descrittive del numero di dataset pubblicati per anno; visualizzazioni esplorative per identificare pattern non immediatamente evidenti dai dati grezzi.
Queste tecniche hanno permesso di ricostruire la dinamica di crescita dell’ecosistema OGD lombardo, evidenziando i momenti di maggiore intensità nella pubblicazione e le aree tematiche che hanno ricevuto più attenzione nel tempo.
Mappatura dei dataset OGD lombardi
Il dataset analizzato, scaricato il 2 dicembre 2025, comprende 5.271 dataset complessivamente pubblicati o catalogati all’interno della piattaforma Open Data Lombardia. Queste risorse provengono da circa 200 enti differenti, tra cui Regione Lombardia, agenzie regionali, enti strumentali, aziende pubbliche e numerosi comuni.
Chi pubblica più dataset
La prima dimensione analizzata riguarda il numero di dataset attribuiti a ciascun ente, con l’obiettivo di identificare gli attori più attivi e il grado di distribuzione della produzione di OGD sul territorio regionale. È importante sottolineare che la piattaforma attribuisce ogni dataset a un ente specifico, e tendenzialmente questa informazione (più che il soggetto materialmente incaricato della pubblicazione tecnica) consente di leggere il ruolo istituzionale dei diversi attori nella produzione dei dati aperti.
Prima di tutto è importante sottolineare ben 783 dataset non sono attribuiti a nessun ente (“NA”), una quota significativa del catalogo. Questa mancanza segnala delle criticità nella qualità dei metadati o in alcune pratiche di catalogazione, con impatti evidenti sulla trasparenza e sulla tracciabilità dei dati.
L’ente che figura come principale produttore di open data è Regione Lombardia, con ben 2062 dataset, pari a circa il 39% dell’intero catalogo. A seguire: ARPA Lombardia (303 dataset), PoliS Lombardia (223 dataset), Città Metropolitana di Milano (190 dataset), e ARIA Lombardia (68 dataset).
Il contributo dei comuni lombardi è particolarmente variegato. Si distinguono alcuni casi virtuosi, come il Comune di Arese (94 dataset) e il Comune di Cremona (73 dataset). La maggior parte dei comuni, tuttavia, pubblica un numero contenuto di dataset, generalmente inferiore a 50. Nel complesso, la media dei dataset attribuiti ai comuni lombardi è pari a 10,8. Ciò pare indicare che alcuni enti locali nel corso degli ultimi anni sono riusciti a sviluppare una pratica strutturata di pubblicazione dei dati, la maggioranza opera in modo più sporadico o con risorse limitate.

Chi produce i dataset attribuiti alla Regione
Poiché Regione Lombardia risulta l’ente a cui è attribuito il maggior numero di dataset, è utile approfondire la struttura interna della produzione dei dati per comprendere chi, all’interno o in relazione alla Regione, contribuisce in modo più significativo al catalogo open data.
Un’informazione utile ci arriva dai proprietari dei dataset i.e., i soggetti a cui è formalmente attribuita la responsabilità del dataset. L’analisi degli owner consente di evidenziare quali uffici, iniziative o attori interni/esterni alimentino maggiormente l’offerta informativa regionale. Dall’analisi risulta che la stragrande maggioranza dei dataset (oltre il 64% di quelli attribuiti alla Regione) è direttamente associata all’account istituzionale “Regione Lombardia”, indicando un processo centralizzato di pubblicazione o di accentramento dei metadati.
Al secondo posto si colloca l’Osservatorio Epidemiologico con 152 dataset, una quota significativa che riflette l’aumento della produzione di dati sanitari e epidemiologici nel periodo pandemico e post-pandemico. Questa presenza conferma il ruolo cruciale ricoperto dagli OGD nella gestione e nel monitoraggio dell’emergenza, nonché nella fase successiva di analisi e comunicazione pubblica.
Oltre a questi due poli principali, emerge un insieme molto eterogeneo di owner minori (dipendenti pubblici, unità amministrative, enti locali e iniziative civiche) ciascuno dei quali contribuisce con un numero più contenuto di dataset.
Questa variegata rete di contributori può essere letta da un lato, come segnale positivo di pluralità e iniziativa diffusa. Allo stesso tempo, è anche possibile che la varietà sia un indicatore di una mancanza di piena standardizzazione nei processi di attribuzione e gestione dei dataset, con conseguenti variazioni nella qualità e coerenza dei metadati.
Andamento delle pubblicazioni dei dataset
Per comprendere come si sia sviluppato l’ecosistema degli open data in Lombardia, è indispensabile osservare quando i dataset sono stati pubblicati. La data di prima pubblicazione associata a ogni risorsa permette, infatti, di ricostruire l’evoluzione del catalogo e di individuare eventuali momenti di accelerazione, rallentamento o cambi di strategia.

Nei primi anni di attività, tra il 2012 e il 2015, la crescita è lenta ma costante: si passa da 59 dataset nel 2012 a 222 nel 2015. Questa è certamente una prima fase di sperimentazione in cui la Regione e gli altri enti iniziano a familiarizzare con la logica degli OGD. Questo periodo corrisponde con l’inizio della popolarizzazione degli OGD anche all’interno del dibattito accademico (cfr. Gao et al., 2023; Janssen et al., 2012). L’incremento nei primi anni rimane comunque contenuto, nonostante segnali l’emergere di un interesse crescente verso la pubblicazione strutturata degli OGD.
A partire dal 2015 il ritmo comincia a cambiare: tra il 2015 e il 2017 il numero di nuovi dataset pubblicati ogni anno raddoppia e supera, in modo costante, la soglia dei 400. Questo periodo coincide con un chiaro consolidamento organizzativo e tecnologico dell’infrastruttura regionale per i dati aperti, accompagnato da una maggiore consapevolezza (e forse anche da un certo entusiasmo) da parte degli enti pubblici del ruolo che gli open data possono svolgere in termini di trasparenza, accountability e supporto all’innovazione.
Come evidente dal grafico in figura, Il 2018 rappresenta un punto fuori scala. Con 1.424 dataset pubblicati in un solo anno, il catalogo registra un picco molto superiore a quello osservato negli anni precedenti e successivi. Questo traguardo non può essere interpretato come il semplice risultato di una crescita incrementale, ma sembra piuttosto legato a un’ampia operazione di popolamento del catalogo: la migrazione di dataset già prodotti, la sistematizzazione di archivi esistenti o l’allineamento a nuovi standard nazionali e regionali. Il 2018 segna quindi un momento di eccezionale accelerazione, che ridefinisce completamente la dimensione dell’offerta di OGD in Lombardia.
Non è semplice ricostruire le motivazioni che stanno alla base di questo picco di pubblicazioni. Sicuramente, il picco è dovuto in parte al fatto che nel 2018 la Regione ha promosso una serie di iniziative mirate a incoraggiare gli enti locali a pubblicare dati sul portale regionale, mettendo a disposizione sia co-finanziamenti che supporto tecnico per facilitare la pubblicazione e l’automazione dei processi.
In particolare, la proposta di co-finanziare la pubblicazione di open data da parte degli enti locali con criteri di automazione e la definizione di un “paniere” di dataset da cui attingere ha spinto numerosi comuni e altre amministrazioni del territorio ad aderire attivamente all’iniziativa. Questo percorso ha portato Regione Lombardia ad aggiornare formalmente i suoi criteri per la pubblicazione degli open data, con una delibera specifica approvato nell’anno stesso.
La delibera Regionale che aggiorna i “Criteri per l’Open Data” rappresenta certamente una tappa importante nel percorso di consolidamento della governance dei dati aperti, che ha avuto come obiettivo allineare la regione alle nuove linee nazionali ed europee e di rafforzare il ruolo del portale come punto di riferimento per la diffusione degli OGD. Possiamo dunque interpretare il picco di pubblicazione dei dataset come un risultato positivo ottenuto dalle politiche messe in atto dalla regione.
Dopo questo picco, il numero di pubblicazioni annuali si riduce ma rimane comunque più alto rispetto ai livelli pre-2018. Nel 2019 i dataset pubblicati sono 740, quasi il doppio rispetto alla media del periodo 2015–2017. Nel 2020 e 2021 la curva scende ulteriormente, attestandosi rispettivamente a 394 e 324 dataset. L’andamento di questi anni è probabilmente influenzato anche dagli effetti organizzativi della pandemia, che da un lato ha spostato l’attenzione delle amministrazioni verso attività emergenziali, dall’altro ha reso centrale la disponibilità di dati epidemiologici e sanitari.
Negli anni più recenti (2022–2025) si osserva un nuovo assestamento: il numero di dataset pubblicati ogni anno oscilla stabilmente tra i 200 e i 300. E un ritmo certamente meno sostenuto rispetto alla fase espansiva, ma più regolare e indicativo di una certa maturità raggiunta. Possiamo suppore che a questo punto gli enti si soffermino più sulla manutenzione, sull’aggiornamento e sulla qualità dei dati, piuttosto che sull’ampliamento quantitativo del catalogo.
Nel complesso, la serie storica mostra quindi un’evoluzione articolata in tre grandi momenti: una fase di avvio graduale, una fase di grande espansione culminata nel picco del 2018 e, infine, una fase di stabilizzazione che riflette un ecosistema ormai consolidato e orientato a pratiche di pubblicazione più selettive e strutturate.
Categorie dei dataset pubblicati
Per comprendere meglio la natura dell’ecosistema OGD lombardo è ovviamente altresì fondamentale analizzare anche che tipi di dataset vengono pubblicati. La classificazione tematica dei dati permette infatti di individuare le aree in cui gli enti pubblici investono maggiormente, così come quelle meno presidiate, offrendo così una lettura strutturata delle priorità informative della pubblica amministrazione regionale. La distribuzione dei dataset per categoria rivela un panorama eterogeneo ma anche piuttosto sbilanciato, con alcune aree nettamente più rappresentate di altre.
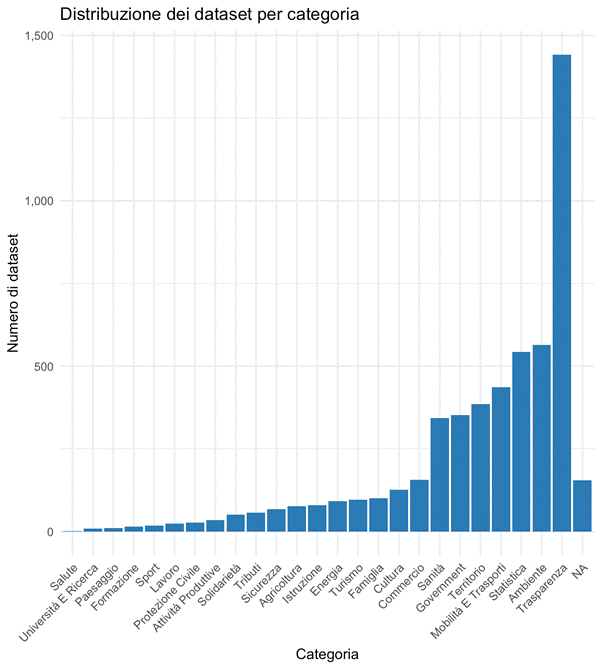
La categoria più rappresentata è di gran lunga quella relativa alla Trasparenza amministrativa, con 1.442 dataset, pari a oltre un quarto dell’intero catalogo. Questo risultato riflette sicuramente l’impatto normativo del quadro legislativo italiano ed europeo, che negli ultimi anni ha spinto le PA a pubblicare dati relativi a bandi, incarichi, appalti, organigrammi e performance. La forte presenza di questa categoria suggerisce che la piattaforma regionale è stata utilizzata anche come strumento per adempiere agli obblighi di trasparenza amministrativa, consolidando così la funzione degli OGD come leva per l’accountability pubblica.
Subito dopo la trasparenza emergono tre aree tematiche che descrivono bene la missione informativa della Regione Lombardia: Ambiente (564 dataset), Statistica (543 dataset), Mobilità e Trasporti (436 dataset). La forte presenza dei dataset ambientali è coerente con la tradizionale produzione dati di ARPA e con il crescente interesse pubblico verso la qualità dell’aria, il consumo di suolo e i fenomeni climatici. La categoria Statistica, invece, rappresenta l’insieme di dati socio-demografici, economici e territoriali prodotti da uffici regionali e centri di ricerca: un patrimonio essenziale per analisi e politiche evidence-based. La Mobilità, da sempre un tema centrale per una regione densamente urbanizzata come la Lombardia, riflette la disponibilità di dati su traffico, trasporto pubblico, infrastrutture e rete viaria.
Le categorie Territorio (385 dataset), Government (353) e Sanità (344) presentano anche una buona quantità di risorse. La presenza della Sanità appare particolarmente significativa alla luce della pandemia, durante la quale la domanda di dati pubblici è cresciuta rapidamente; tuttavia, il numero complessivo rimane più contenuto rispetto ad altre categorie, segno probabilmente della complessità legata alla pubblicazione di dati sanitari e alla necessità di garantire tutele stringenti in materia di privacy.
La presenza di 155 dataset nella categoria “NA” indica che una parte delle risorse non è associata a nessuna categoria tematica. Questa assenza di classificazione può dipendere da metadati incompleti o inseriti in modo non uniforme e rappresenta certamente una criticità per l’usabilità del catalogo.
Nel complesso, la distribuzione tematica dei dataset lombardi evidenzia un ecosistema informativo fortemente orientato alla trasparenza e all’accountability, alla gestione del territorio e dell’ambiente, alla mobilità e ai servizi pubblici essenziali, e alla produzione statistica istituzionale.
Focus Regione Lombardia: categorie dei dataset attribuiti
Poiché Regione Lombardia è l’ente a cui è attribuito il maggior numero di dataset nell’intero catalogo, è utile osservare più da vicino quali sono le categorie tematiche che caratterizzano la sua produzione di OGD. Osservando i dataset attribuitivi, emerge una distribuzione tematica che riflette in modo chiaro le priorità dell’ente. La categoria più rilevante è Trasparenza, con 825 dataset, a conferma del ruolo centrale che la Regione svolge nel rendere pubblici dati su bandi, appalti, incarichi e performance amministrativa.

Al secondo posto troviamo la Sanità con 316 dataset, un valore significativo che testimonia la centralità del settore nel modello lombardo e l’eredità informativa della pandemia, durante la quale la produzione e la richiesta di dati sanitari è aumentata in modo sostanziale. Seguono categorie più strettamente legate alle funzioni amministrative e di regolazione della Regione: Government (172), Commercio (115) e Mobilità e Trasporti (102), che rappresentano le aree in cui l’ente esercita maggiori competenze di coordinamento e indirizzo. Le altre categorie mostrano invece numeri più contenuti.
Andamento negli anni delle categorie dei dataset pubblicati
Osservando la distribuzione dei dataset per anno e per categoria emerge un quadro decisamente più ricco e articolato, che può in qualche modo riflettere sia l’evoluzione delle priorità politiche e amministrative della Regione Lombardia sia le dinamiche di maturazione dell’intero ecosistema open data.

Come abbiamo precedentemente visto, nei primi anni di attività (2012–2015) la pubblicazione dei dataset è ancora relativamente limitata, ma già caratterizzata da una certa varietà per quel che riguarda i temi. In questo periodo si notano incrementi graduali in categorie come Statistica, Territorio, Cultura e Commercio, che rappresentano le tipiche aree su cui gli enti iniziano a sperimentare la pubblicazione di OGD. È interessante notare come in questa fase la categoria Sanità rimanga sostanzialmente marginale: il numero di dataset sanitari è molto contenuto, segno che prima del 2018 l’informazione sanitaria non costituiva ancora un ambito di investimento strutturato nell’open data regionale, probabilmente anche per la sensibilità dei dati trattati e per l’assenza di una forte domanda pubblica.
Tra 2016 e 2017 si osserva un aumento progressivo nelle categorie Cultura, Istruzione, Solidarietà e soprattutto Statistica, che inizia a diventare una componente stabile del catalogo (31 dataset sia nel 2015 sia nel 2017). Sono gli anni in cui gli enti regionali e locali prendono maggiore confidenza con la piattaforma e iniziano a strutturare meglio i flussi di pubblicazione.
Il 2018 segna un’accelerazione straordinaria nella pubblicazione dei dataset: il picco precedentemente osservato sul totale annuo si riflette in modo evidente anche nelle singole categorie. In questo anno aumentano drasticamente i dataset in quasi tutte le aree: Statistica passa a 283 dataset, diventando la categoria con la crescita più evidente; Territorio raggiunge 148 dataset, indicando una forte attività di pubblicazione geospaziale o territoriale; Famiglia registra 54 dataset, un valore molto superiore agli anni precedenti; Commercio (70) e Cultura (36) mostrano anch’essi incrementi molto significativi.
L’ampiezza e la trasversalità di questa crescita suggeriscono che nel 2018 sia avvenuto un lavoro di popolamento massivo del catalogo, forse legato all’allineamento a nuovi standard, all’integrazione di archivi precedentemente non pubblicati o a progetti finanziati che hanno accelerato la pubblicazione. Dopo il picco del 2018, il numero di dataset diminuisce in quasi tutte le categorie, ma il livello rimane comunque tendenzialmente più alto rispetto al periodo pre-2018.
Nel 2020–2021 si osserva una contrazione in categorie come Cultura, Commercio, Solidarietà e Istruzione, mentre altre (ad esempio Statistica) mostrano una discreta continuità (12 dataset nel 2020, 33 nel 2021). In questi anni assume un ruolo più rilevante la categoria Sanità, che pur non raggiungendo i volumi delle categorie maggiori, mostra una presenza più stabile e significativa rispetto agli anni precedenti. È plausibile che la pandemia abbia contribuito a questo incremento: anche se la pubblicazione di open data sanitari rimane complessa per motivi normativi, l’emergenza ha aumentato la pressione sulla produzione e condivisione di dati epidemiologici, di monitoraggio e di supporto alle decisioni pubbliche.
Negli ultimi quattro anni (2022-2025) la pubblicazione di nuovi dataset si stabilizza su livelli più contenuti. Le categorie meno strutturate, come Cultura, Commercio, Sport o Solidarietà, mostrano una presenza sporadica, mentre altre categorie più robuste, come Statistica, continuano a garantire un flusso costante di nuove risorse, seppur più moderato rispetto al 2018–2019. Anche la categoria Sanità si mantiene presente in modo costante, segno che l’esperienza pandemica ha lasciato un’eredità informativa che continua a tradursi in un’attività di pubblicazione più regolare rispetto al passato.
Indicatori di utilizzo: download e visualizzazioni dei dataset
Valutare l’utilizzo e l’impatto degli open data è sempre un’operazione estremamente complessa. I dataset, una volta pubblicati, circolano infatti al di fuori dei confini delle piattaforme istituzionali: vengono integrati in applicazioni, incorporati in analisi, rielaborati da terzi, oppure scaricati una sola volta e riutilizzati per anni. Il loro ciclo di vita è molto più complesso di quanto i sistemi di monitoraggio riescano a catturare. Regione Lombardia ha sul proprio portale una pagina in cui ha raccolto alcuni esempi di riutilizzo che sono stati segnalati.
Iniziamo osservando due indicatori aggregati: il numero totale dei download e il numero totale delle visualizzazioni delle pagine dei dataset.


Guardando ai download, emerge chiaramente che alcune categorie attirano un uso più intensivo. La Trasparenza amministrativa è quella che registra il numero più alto, con oltre un milione di download: un dato in linea con la centralità di questi dataset nell’attività di monitoraggio civico, giornalistico e amministrativo. Subito dopo troviamo la categoria Agricoltura, con oltre 900.000 download, un risultato sorprendente se confrontato con la sua modesta numerosità. Questo dato lascia intuire un forte utilizzo professionale dei dataset agricoli, probabilmente da parte di tecnici, imprese e ricercatori che lavorano su suolo, produzione, uso delle risorse e monitoraggio ambientale. Altre categorie mostrano dinamiche coerenti con quanto emerso nelle sezioni precedenti: Statistica, con più di 800.000 download, conferma la propria natura trasversale, mentre la categoria Sanità, con oltre 630.000 download, raggiunge livelli molto consistenti. Quest’ultimo valore riflette senz’altro l’importanza dei dati sanitari negli ultimi anni, soprattutto nel periodo pandemico, quando informazioni su contagi, ospedalizzazioni e servizi territoriali sono diventate risorse centrali per cittadini, media e decisori pubblici.
Le visualizzazioni offrono un quadro complementare. Qui la categoria più consultata non è Trasparenza, bensì quella della Sanità, che supera 1,3 milioni di visite. È un dato molto significativo: i dataset sanitari, più di altri, sembrano attrarre una fruizione immediata, spesso orientata alla semplice consultazione piuttosto che al download per un riuso avanzato. È un comportamento decisamente coerente con quanto abbiamo osservato nella fase pandemica, quando molte persone visitavano frequentemente pagine che riportavano dati aggiornati sull’andamento epidemiologico senza necessariamente scaricare i dataset originali.
La Trasparenza amministrativa rimane comunque una delle categorie più viste, segno che anche in questo caso la consultazione diretta delle informazioni gioca un ruolo importante. Statistica, Ambiente e Territorio si confermano aree tematiche molto frequentate, probabilmente perché offrono dati utili per comprendere fenomeni sociali e ambientali di largo interesse.
La differenza tra visualizzazioni e download potrebbe essere dovuta al fatto che alcune categorie (es: Sanità) contengono informazioni che rispondono a un’esigenza di consultazione immediata, spesso legata all’attualità o a fenomeni rapidamente mutevoli. In questi casi l’utente ha bisogno di leggere il dato, non necessariamente di scaricarlo. Altre categorie, come Trasparenza o Statistica, si prestano probabilmente invece a un utilizzo più tecnico: chi cerca questi dataset tende spesso a scaricarli per svolgere analisi approfondite, confronti, visualizzazioni personalizzate o integrazioni in sistemi informativi. Non stupisce quindi che Trasparenza sia la categoria più scaricata, pur rimanendo secondaria nelle visualizzazioni.
Se l’osservazione dei valori aggregati consente di individuare le categorie che, complessivamente, attraggono un uso più intensivo, essa non restituisce però informazioni sull’evoluzione di questo utilizzo nel tempo. I volumi totali di download e visualizzazioni tendono infatti ad appiattire dinamiche molto diverse, mettendo sullo stesso piano fasi storiche caratterizzate da livelli di attività profondamente differenti. Per comprendere meglio come e quando l’ecosistema open data regionale abbia iniziato a essere effettivamente utilizzato, è quindi necessario adottare una prospettiva temporale e osservare l’andamento dei file di dati scaricati nel corso degli anni.
L’analisi longitudinale dei download mostra con chiarezza che l’utilizzo dei dati aperti di Regione Lombardia non è stato costante nel tempo, ma è attraversato da una forte discontinuità. È un cambiamento rilevante perché non si tratta dell’emergere isolato di singole categorie particolarmente attrattive, ma di un rafforzamento complessivo dell’ecosistema OGD, all’interno del quale alcune aree tematiche assumono un ruolo trainante. L’analisi dell’andamento dei download per categoria nel tempo consente quindi di distinguere tra usi consolidati e di lungo periodo, dinamiche più episodiche e fasi di accelerazione che riflettono mutamenti più ampi nel contesto istituzionale e sociale.

L’analisi di lungo periodo dei download dei dataset pubblicati sul portale open data di Regione Lombardia evidenzia innanzitutto una netta discontinuità temporale. Fino al 2020 per l’insieme delle principali categorie tematiche, i volumi annuali rimangono generalmente al di sotto delle 100 mila unità complessive, con valori spesso inferiori alle 50 mila. In questa fase iniziale, l’utilizzo dei dati aperti appare limitato e frammentato, suggerendo un ecosistema ancora poco maturo e con pratiche di riuso debolmente consolidate.
A partire dagli anni successivi al 2020 si osserva invece una crescita generalizzata e simultanea dei download in tutte le categorie principali. Questo aumento non riguarda una singola area tematica, ma interessa l’intero portale, indicando un cambiamento strutturale nell’intensità di utilizzo dei dati aperti. Negli anni più recenti, i download complessivi delle sole prime dieci categorie più numerose superano di gran lunga i livelli precedenti, con incrementi di uno o due ordini di grandezza rispetto al periodo pre-2020.
All’interno di questa dinamica generale, emergono differenze significative tra categorie. Agricoltura rappresenta la categoria nettamente dominante: sull’intero periodo analizzato totalizza oltre 73 milioni di download, di cui più di 36 milioni concentrati nell’ultimo anno disponibile. Questo dato segnala non solo un forte incremento recente, ma anche una centralità strutturale della categoria, che da sola supera ampiamente tutte le altre in termini di volume complessivo.
La categoria Sanità segue con circa 46 milioni di download complessivi, di cui quasi 22 milioni nell’ultimo anno. Il suo andamento è caratterizzato da una crescita molto accentuata nel periodo post-2020, con livelli di utilizzo che rimangono elevati anche al di fuori dei picchi più evidenti. Ciò suggerisce una domanda di dati sanitari stabile e trasversale, probabilmente legata sia a esigenze informative istituzionali sia a pratiche di analisi e monitoraggio più ampie.
Un ruolo particolarmente rilevante è assunto anche da Trasparenza Amministrativa, che raggiunge oltre 32 milioni di download totali, con più di 18 milioni concentrati nell’ultimo anno. In questo caso, la crescita appare fortemente concentrata negli anni più recenti, indicando un rafforzamento progressivo dell’uso dei dati legati all’accountability e al controllo dell’azione amministrativa, in particolare nel periodo post-2020.
Turismo e Cultura presentano volumi complessivi simili, rispettivamente intorno ai 32 milioni e ai 25 milioni di download. Tuttavia, le due categorie mostrano andamenti differenti: mentre Cultura concentra circa 11,7 milioni di download nell’ultimo anno, suggerendo una crescita recente e significativa, Turismo presenta una distribuzione più discontinua, con circa 8,2 milioni di download nell’ultimo anno, a fronte di forti oscillazioni nel tempo. Questo pattern indica un utilizzo più sensibile a contingenze specifiche e cicli di attenzione.
Le restanti categorie principali (Statistica, Mobilità e trasporti, Ambiente, Territorio e Sport) mostrano volumi complessivi inferiori rispetto ai casi dominanti, ma seguono anch’esse la traiettoria generale di crescita post-2020. In particolare, Ambiente e Territorio, pur partendo da valori molto bassi nel periodo 2012–2015, registrano incrementi progressivi e costanti negli anni successivi, segnalando un interesse emergente che si consolida nel tempo.
Nel complesso, i dati mostrano come l’ecosistema open data regionale sia caratterizzato da una fase iniziale di utilizzo limitato, seguita da una svolta netta negli anni successivi al 2020, in cui tutte le principali categorie registrano un aumento significativo dei download. Questa dinamica suggerisce che il rafforzamento del riuso dei dati aperti non sia attribuibile a singole categorie, ma a un cambiamento più ampio nelle pratiche di accesso, utilizzo e valorizzazione degli OGD.
Bibliografia
Gao, Y., Janssen, M., & Zhang, C. (2023). Understanding the evolution of open government data research: Towards open data sustainability and smartness. International Review of Administrative Sciences, 89(1), 59–75. https://doi.org/10.1177/00208523211009955
Janssen, M., Charalabidis ,Yannis, & and Zuiderwijk, A. (2012). Benefits, Adoption Barriers and Myths of Open Data and Open Government. Information Systems Management, 29(4), 258–268. https://doi.org/10.1080/10580530.2012.716740
Kassen, M. (2019). Open Data Politics: Building a Research Framework. In M. Kassen (Ed.), Open Data Politics: A Case Study on Estonia and Kazakhstan (pp. 1–18). Springer International Publishing. https://doi.org/10.1007/978-3-030-11410-7_1
Maretti, M., Russo, V., & del Gobbo, E. (2021). Open data governance: Civic hacking movement, topics and opinions in digital space. Quality & Quantity, 55(3), 1133–1154. https://doi.org/10.1007/s11135-020-01045-y
Risorse e dataset utilizzati
Statistiche mensili opendata – Somme visite e download https://www.dati.lombardia.it/Government/Statistiche-mensili-opendata-Somme-visite-e-downlo/kent-7ktz/about_data
Elenco risorse Open Data Regione Lombardia: https://www.dati.lombardia.it/government/Elenco-risorse-opendata-pubblicate/425r-pyq4/about_data











