

I graph database non sono più visti solo come una tecnologia ma come un potente strumento. Uno strumento che può aiutare a scoprire frodi nel settore assicurativo o nel mondo finanziario, così come aiutare a selezionare i migliori principi attivi che permettono di produrre un nuovo farmaco, riducendo al minimo gli effetti collaterali.
Indice degli argomenti
Graph database: un mercato in forte crescita
Se i graph database fino a qualche anno fa erano poco conosciuti o visti come una tecnologia non ancora matura, oggi sono quindi visti come strettamente necessari per le aziende. Non a caso Gartner ha inserito i graph database e le tecnologie correlate tra i dieci trend che stanno cambiando il volto della gestione dei dati e degli analytics.
Le tecnologie, le applicazioni e i servizi che ruotano intorno ai graph database, sono quindi da monitorare con attenzione per interesse, per opportunità o perché possono fornire una risposta alle nuove esigenze dei diversi dipartimenti aziendali. Dagli algoritmi di raccomandazione, alla gestione delle autorizzazioni in ambito di sicurezza, sono sempre più le applicazioni abilitate dai graph database.
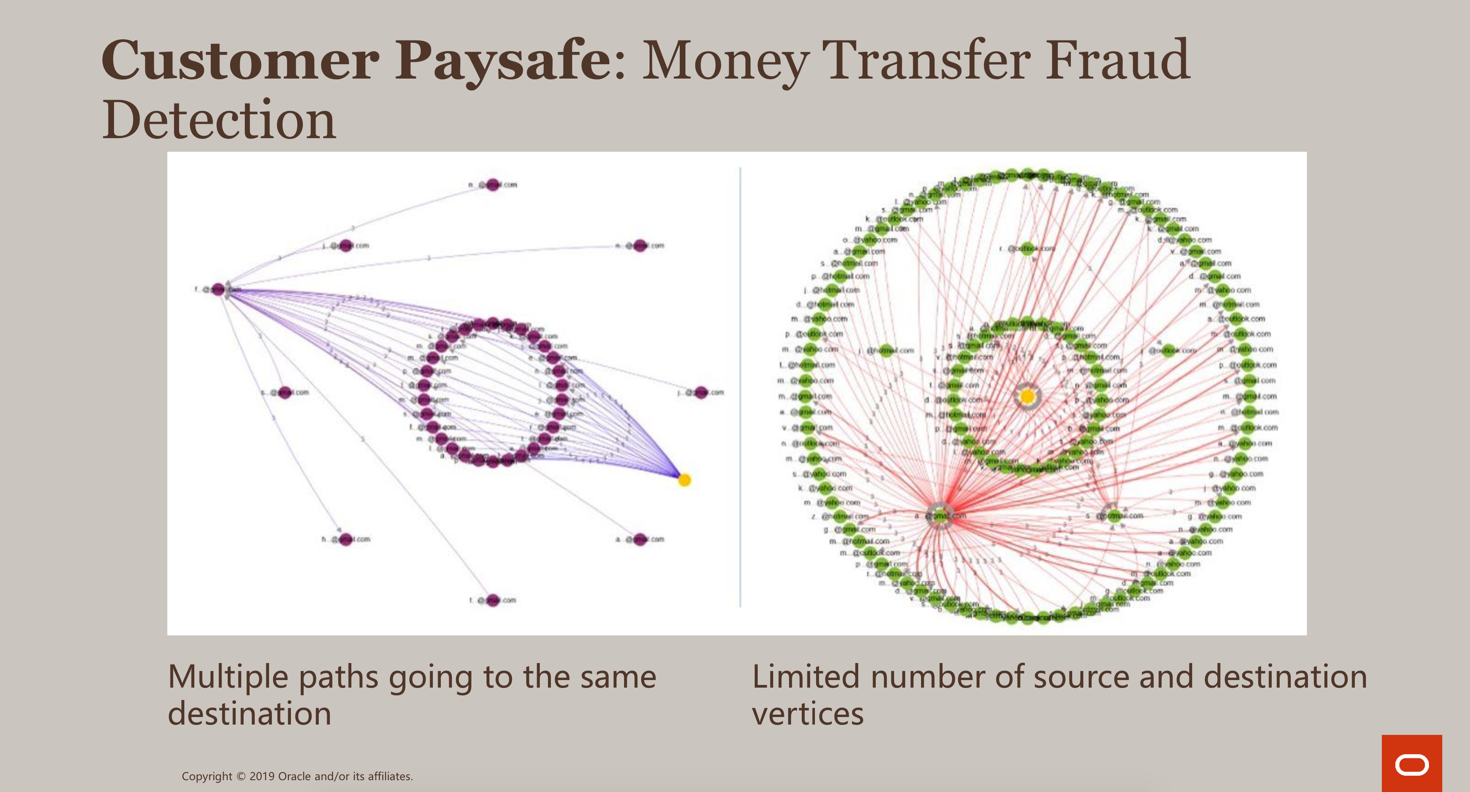
Slide tratta dalla presentazione di Melli Annamalai, Product Manager di Oracle
Che questo mercato sia in fermento lo dimostra anche l’interesse dei venture capitalist e delle società di investimento, come è emerso anche nel corso della edizione 2019 dell’importante Graphorum Conference.
A fine ottobre, Stardog, società statunitense, uno dei vendor di riferimento di questo mercato ha ottenuto un finanziamento di nove milioni di dollari per accelerare la propria crescita e espansione sul mercato. Solo qualche giorno fa, Siren, società irlandese fondata dall’italiano Giovanni Tummarello, ha annunciato di aver ottenuto un finanziamento di dieci milioni di dollari. Siren basa i propri servizi e le proprie applicazioni su una piattaforma che può gestire e indicizzare miliardi di relazioni. Ancora più elevato è stato il finanziamento ottenuto da TigerGraph, società californiana, con una sede di fronte a quella di Oracle e che a settembre ha ottenuto un finanziamento di ben 32 milioni di dollari.
Knowledge Graph vs Property Graph
Il termine più ricorrente nella conferenza è stato Knowledge Graph.
Knowldge Graph non rappresenta più solo la funzionalità offerta dal motore di ricerca di Google per aiutare gli utenti a cercare le informazioni più rapidamente e in modo più intuitivo. Knowledge Graph è diventata l’etichetta adottata da tutti i vendor di tecnologie del Web Semantico. Tecnologie e standard che hanno faticato ad emergere, come RDF, OWL, Sparql, per lungo tempo limitate al mondo accademico, vivono oggi un momento di fortissimo interesse, anche commerciale. Pensiamo alle specifiche RDF, Resource Description Framework, adottate come raccomandazione esattamente venti anni fa. Queste sono alla base del modello dati oggi etichettato come Semantic Knowledge Graph o più semplicemente come Knowledge Graph. Vendor come Stardog, Cambridge Semantics, Ontotext, Openlink hanno implementato questo modello che oggi è in competizione con il modello alternativo, più giovane di dieci anni e denominato Property Graph sposato da vendor come Neo4j, TigerGraph, ArangoDb, OrientDb, JanusGraph e altri.
Due modelli dati distinti che impongono una scelta ai potenziali clienti di graph database. Diverse sessioni della conferenza hanno evidenziato le differenze tra Semantic Knowledge Graph (chiamati anche Triple Store o RDF Graph) e i Property Graph. Una delle differenze è rappresentata dal fatto che i Semantic Knowledge Graph si basano su standard che garantiscono una interoperabilità che i Property Graph faticano a trovare: un unico linguaggio di interrogazione, Sparql, così come per definire ontologie con OWL o per validare dati, sulla base di un insieme di condizioni, con SHACL (Shapes Constraint Language). Un’altra importante differenza è la capacità deduttiva che i Semantic Knowldge Graph offrono come funzionalità base, una capacità di ottenere nuove informazioni o relazioni, senza scomodare l’utilizzo di intelligenza artificiale. Naturalmente anche i Property Graph hanno molti punti di forza e si dimostrano più adatti quando per rispondere alle richieste degli utenti è necessario attraversare molti nodi del grafo, individuare schemi simili a ad un pattern specificato dall’utente (path analytics), per individuare il cammino tra due nodi di costo minimo o altri algoritmi di ottimizzazione su grafi.
Amazon Web Services da esattamente due anni propone Neptune, un graph database, naturalmente solo in cloud. Amazon ha semplificato questo dualismo e soddisfare tutti i potenziali clienti, offrendo entrambi i modelli dati, Semantic Knowledge Graph e Property Graph. È interessante notare come le differenze strutturali tra i due modelli dati si stiano riducendo grazie a quelli che potrebbero diventare dei nuovi standard, come RDF* e Sparql* e che alcuni vendor come Cambridge Semantics hanno già implementato nei propri prodotti. Una presentazione è stata dedicata a GQL, Graph Query Language, il nuovo progetto ISO creato per definire un nuovo linguaggio standard di interrogazione dei Property Graph. Ogni vendor di Property Graph ha infatti il proprio linguaggio di interrogazione: Neo4j propone Cypher, TigergGraph il suo potente GSQL, ArangoDB AQL. Il fatto che GQL sia un progetto sviluppato e mantenuto dallo stesso ente che ha definito il linguaggio SQL garantisce che presto esisterà un modo unico di interrogare diverse implementazioni di Property Graph, usando la stessa sintassi.
A proposito del dualismo tra i due modelli, secondo un esperto del settore i Semantic Knowledge Graph saranno utilizzati in futuro solo in ambiti molto circoscritti mentre i Property Graph saranno la scelta per la maggior parte delle nuove implementazioni di graph database.
A ben vedere non ci è sembrato così: l’area espositiva della Conferenza era equamente occupata da vendor e system integrator che presentavano prodotti e soluzioni basate su entrambi i modelli. Pensando ai contenuti c’è stato anzi uno squilibrio, con un maggior numero di sessioni dedicate ai Semantic Knowledge Graph.
Conclusioni
Graphorum è stata la conferma che i graph database rappresentano oggi una tecnologia matura, pronta per essere utilizzata all’interno delle aziende. Oggi ha senso domandarsi non se ma quando è opportuno introdurre un graph database in azienda: sicuramente nella vostra azienda, accanto ai consolidati database relazionali e non, ci sarà presto un graph database.
A chiederlo saranno i data scientist per estrarre nuove informazioni, il marketing per raccomandare, in tempo reale, nuovi prodotti ai propri clienti o per capitalizzare l’enorme mole di informazioni non strutturate presenti in azienda che altrimenti rimarrebbero un’inutile, sequenza di bit, comunque da gestire.











Partecipa alla community