

In alcuni settori applicativi all’interno dei quali affidiamo alle intelligenze artificiali la nostra sicurezza fisica, le potenziali vulnerabilità dei sistemi di IA potrebbero rivelarsi un pericoloso boomerang. Basti pensare alle cosiddette self-driving cars (veicoli a guida automatica) o ai velivoli dotati di sistemi di pilotaggio/atterraggio semi-automatico.
In questo articolo, proveremo a fare un po’ di chiarezza su questo problema, discutendo, da una parte, i principali vettori di attacco che possono essere utilizzati per confondere un sistema di IA, in diversi contesti applicativi e, dall’altra, le contromisure più promettenti volte a mitigare questo rischio.
Indice degli argomenti
Intelligenza Artificiale e apprendimento profondo
Per disambiguare il significato dell’espressione “Intelligenza Artificiale” è necessario fare un preliminare distinguo. Nel contesto di questo articolo, quando si parla di IA, ci si riferisce prevalentemente ad algoritmi di apprendimento profondo o deep learning, per usare il più diffuso termine anglofono. Questa categoria di algoritmi appartiene al sottoinsieme degli algoritmi di IA noti come algoritmi di apprendimento automatico o machine learning.
In particolare, il termine apprendimento profondo deriva dalla particolare struttura di questi algoritmi, basati perlopiù su reti neuronali profonde, ovvero caratterizzate da molti strati o livelli, connessi in maniera sequenziale.
Riconoscimento e addestramento
Assimilando ogni livello ad una operazione di filtraggio del dato in ingresso, l’intuizione dietro il funzionamento di questi algoritmi è quella di applicare una determinata sequenza di filtri al dato in ingresso (ad esempio, una immagine rappresentante un determinato oggetto). Ogni livello, o filtro, è caratterizzato da un insieme di neuroni che vengono attivati solo quando percepiscono una determinata struttura (“pattern”) al loro ingresso. Questo meccanismo permette di costruire rappresentazioni più astratte dell’oggetto che si vuole riconoscere fino a poterne determinare la classe di appartenenza. Nella fattispecie, classificare correttamente l’oggetto rappresentato nell’immagine.
Questo comportamento è schematizzato in Fig. 1.
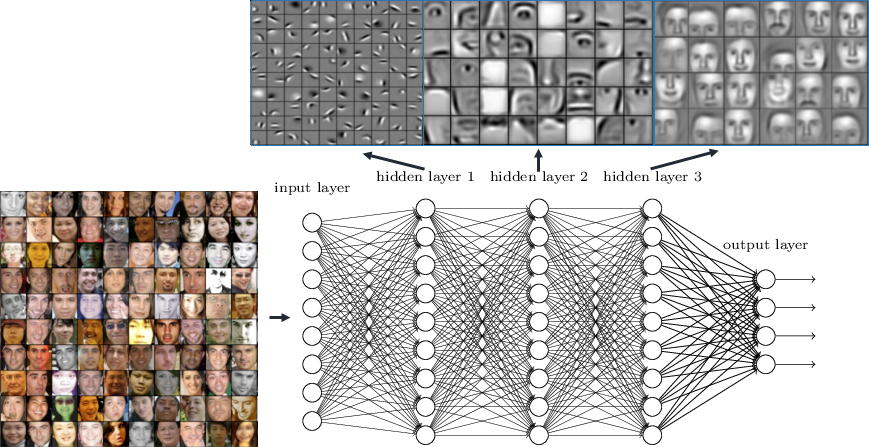
Fig. 1. Esempio delle rappresentazioni imparate ai diversi livelli da una rete neurale profonda in un problema di riconoscimento dei volti. Si noti come, attraversando i vari livelli, si passi da rappresentazioni di basso livello (che rilevano bordi, tessiture, ecc.) a rappresentazioni di livello più astratto (dove si riconosce il volto di un determinato soggetto).
La complessità di questi algoritmi sta chiaramente nel costruire queste rappresentazioni in maniera automatica, ovvero nel comprendere come costruire la sequenza di operazioni di filtraggio da applicare al dato in ingresso. A questo scopo, questi algoritmi necessitano di una fase di addestramento, in cui al sistema sono sottoposte diverse immagini di oggetti che il sistema dovrà essere in grado di riconoscere, insieme alla loro etichetta di classe.
Durante la procedura di addestramento, l’algoritmo cerca di predire la classe corretta di questi oggetti e, in caso di errore, corregge i suoi parametri in modo che all’iterazione successiva la predizione risulti diversa, avvicinandosi via via a quella corretta. Alla fine di questo processo, l’algoritmo avrà imparato a distinguere oggetti di classi diverse sulla base di correlazioni statistiche e particolari pattern associati alle diverse tipologie di oggetti presenti nei dati.
Prestazioni super-umane
Stante l’enorme disponibilità di dati che è possibile raccogliere oggi e l’imponente potenza di calcolo dei nuovi calcolatori e delle architetture cloud, in alcuni scenari applicativi specifici, l’apprendimento profondo ha dimostrato di raggiungere perfino prestazioni migliori degli esseri umani.
Un caso emblematico è quello dei videogiochi e dei giochi di strategia. Da tempo gli algoritmi di IA si sono dimostrati molto più bravi degli umani nel gioco degli scacchi, ma ultimamente si stanno dimostrando superiori anche in giochi e videogame molto più complessi, sparatutto inclusi. Di recente, DeepMind ha perfino mostrato che l’IA può imparare autonomamente a sconfiggere giocatori umani molto esperti in un videogame complesso come StarCraft II. Anche in questi casi, la forza degli algoritmi, risiede nella possibilità di poter osservare molti dati, giocare potenzialmente infinite partite e migliorarsi partita dopo partita.
Sono poi numerose le applicazioni dove le reti neuronali profonde hanno stabilito nuovi standard di prestazione, dalla segmentazione e riconoscimento di oggetti nei video, alla diagnosi di particolari malattie fatta a partire da immagini mediche, fino al riconoscimento vocale (si pensi ai numerosi assistenti vocali disponibili oggi sui nostri telefoni cellulari o come assistenti domestici).
Perfino nell’ambito della sicurezza informatica e fisica, l’IA viene ormai usata pervasivamente come ausilio nella rilevazione di attacchi informatici, dalla rilevazione di phishing e domini/siti web malevoli, alla rilevazione di intrusione in reti aziendali, fino a problemi di video sorveglianza in aree critiche.
Stante quanto detto finora, potrebbe sembrare quindi che l’IA e, in particolare, il deep learning siano il nuovo Eldorado, la panacea di tutti i mali. Ma sappiamo bene che non è tutto oro quel che luccica…
Gli algoritmi di IA, nonostante il loro nome altisonante, soffrono di allucinazioni piuttosto particolari. Esistono infatti determinate manipolazioni dei dati forniti in ingresso (input) a questi algoritmi che sono capaci di confonderli, in alcuni casi, anche clamorosamente. L’esempio ostile (dall’inglese adversarial example) più eclatante e popolare è forse quello riportato dal famoso articolo scientifico “Intriguing properties of neural networks”, pubblicato dai ricercatori di Google Brain nel 2013. Questo esempio mostra come un’immagine di uno scuolabus, modificata con un rumore ostile ma impercettibile all’occhio umano, venga erroneamente riconosciuta come l’immagine di uno struzzo.
Dopo questa scoperta, la comunità scientifica si è scatenata, fantasticando di attacchi contro i sistemi di riconoscimento del volto in applicazioni biometriche o forensi, contro i sistemi di riconoscimento dei segnali stradali per i veicoli a guida automatica (Fig. 2) e perfino contro gli assistenti vocali, mostrando come questi ultimi possano essere confusi da un rumore audio quasi impercettibile all’orecchio umano.

Fig. 2. Nell’articolo “Robust Physical-World Attacks on Deep Learning Models” pubblicato nel 2018, alcuni ricercatori hanno dimostrato come ingannare un sistema di riconoscimento dei segnali stradali a bordo di un veicolo a guida automatica, semplicemente posizionando degli adesivi su un segnale di stop. Davanti a questa manipolazione, l’algoritmo è infatti indotto a riconoscere il segnale come un segnale di limite massimo di velocità.
Il problema della (in)sicurezza degli algoritmi di IA
Tuttavia, nonostante l’esuberanza ritrovata dalla comunità scientifica nel 2013, il problema della (in)sicurezza degli algoritmi di IA era già noto da tempo a chi, questi algoritmi, li applicava in problemi di sicurezza informatica.
Già dal 2004, gli algoritmi di IA per il riconoscimento delle email di spam si erano mostrati facilmente vulnerabili ad attacchi mirati, in cui gli spammer potevano alterare il testo delle email senza compromettere la leggibilità del messaggio per gli esseri umani. E, più recentemente, intorno agli anni 2012-2013, il laboratorio di ricerca PRA Lab all’Università di Cagliari aveva già dimostrato come costruire algoritmi di attacco in grado di bucare anche le reti neurali. In particolare, lo scenario descritto sopra, identifica solo una particolare vulnerabilità degli algoritmi di IA. Questo scenario, noto anche come evasion, consiste nel confondere la classificazione del dato in ingresso manipolandone il contenuto, da parte di un algoritmo precedentemente addestrato. In uno scenario differente, noto come poisoning (avvelenamento), l’attaccante può contaminare i dati di addestramento per impedire al sistema di funzionare correttamente. Esistono anche attacchi che sono in grado di estrarre informazioni confidenziali solo analizzando le uscite degli algoritmi di IA su diversi dati in ingresso, violando potenzialmente la privacy di altri utenti. Questo è uno scenario più che plausibile quando questi algoritmi sono fruibili come servizi online.
La ricerca di frontiera e il progetto ALOHA
Il filone di ricerca descritto in questo articolo è parzialmente analizzato, col fine di individuare cause delle vulnerabilità nelle IA e adeguate contromisure, anche all’interno del progetto ALOHA finanziato dall’Unione Europea (programma Horizon 2020, grant agreement n° 780788). L’obiettivo principale del progetto è l’introduzione dell’intelligenza artificiale basata sul Deep Learning nei dispositivi elettronici che permeano la nostra vita di tutti i giorni, in casa, nelle città e nei posti di lavoro. A tale scopo, il progetto ALOHA mira ad abilitare l’uso del Deep Learning, per ora principalmente limitato a server ad alte prestazioni, su sistemi di elaborazione specializzati di nuova generazione, mobili, portatili e a bassissimo consumo di potenza, aprendo la strada verso una nuova vastissima gamma di applicazioni.
I risultati del progetto sono testati in molteplici ambiti: impianti di sicurezza intelligenti, basati sul riconoscimento di video e immagini, da utilizzare in aree di emergenza; speciali catene di montaggio “cognitive”, in grado di reagire in modo rapido e affidabile ai comandi vocali degli operatori, risultando più sicure e confortevoli; dispositivi medici portatili, atti ad analizzare immagini mediche in condizioni critiche (senza accesso a reti di comunicazione, a batteria), come necessario per esempio negli scenari clinici dei paesi del Terzo mondo o per operazioni di soccorso in caso di calamità o situazioni disastrose.
Il progetto è guidato dall’Università di Cagliari, attraverso il laboratorio EOLAB e coinvolge 14 partner provenienti da 7 paesi, tra cui colossi di grosso calibro come ST Microelectronics e IBM. Tra gli altri partner Italiani anche l’Università di Sassari – IDEA lab, e le aziende Reply e Pluribus One, spin-off dell’Università di Cagliari. E proprio quest’ultima, all’interno del progetto ALOHA ha il delicato ruolo oggetto di questo articolo: valutazione della solidità delle reti neurali profonde di fronte a perturbazioni dei dati di input e implementazione di algoritmi di deep learning sicuri (qui una demo).
Le vulnerabilità dell’IA descritte nella prima parte di questo articolo possono sembrare piuttosto incredibili, stante le prestazioni super-umane di questi algoritmi in alcuni ambiti applicativi. Tuttavia, la questione risulta molto meno sorprendente se pensiamo a come questi algoritmi “imparano” dai dati, secondo un processo di ottimizzazione che via via forza l’algoritmo ad imparare correttamente l’etichetta assegnata ad ogni dato di addestramento, modificandone i parametri interni.
In pratica, la vulnerabilità di questi algoritmi è intrinseca al loro funzionamento e alle assunzioni di fondo sotto cui sono stati progettati; nessuno di essi è stato infatti progettato per riconoscere correttamente alcune particolari trasformazioni ostili dei dati in ingresso.
Di recente, la comunità scientifica si è adoperata massicciamente per trovare una soluzione, proponendo una serie di contromisure volte a mitigare il problema. Non tutte queste contromisure si sono dimostrate efficaci ma tra le soluzioni più promettenti alle varie tipologie di attacco, è sempre possibile trovare un denominatore comune: fornire al sistema di IA una conoscenza aggiuntiva su come può comportarsi un attaccante, conoscenza che tipicamente non è e non può essere disponibile nei dati di addestramento.
Questo si può ottenere modificando l’algoritmo di apprendimento usato dall’IA, simulando esplicitamente, in forma matematizzata, la presenza di un attaccante che cerca di manipolare i dati per evadere la rilevazione. Nel contesto del progetto ALOHA, questa strategia ha già portato promettenti risultati nei diversi casi di studio. Altre strategie di difesa riguardano la capacità di rilevare esplicitamente i tentativi di attacco, cercando di identificare quei dati che risultano anomali o sostanzialmente diversi dai dati di addestramento. Queste strategie si sono rilevate particolarmente utili nella rilevazione degli attacchi di poisoning che mirano a contaminare la fase di addestramento dell’IA, mentre rimane più difficile per queste tecniche rilevare gli attacchi di tipo evasivo, nei quali l’attaccante ha più gradi di libertà per costruire manipolazioni ostili.
La sfida è dunque aperta e fornire garanzie di sicurezza per i sistemi di IA rimane tutt’oggi un problema complesso. Alcuni immaginano che, in futuro, i meccanismi di difesa potranno essere completamente automatizzati, mentre altri sostengono che questo non sarà sufficiente e l’esperienza dell’esperto umano rimarrà imprescindibile per migliorare realmente la sicurezza di questi sistemi. La risposta, come sempre, è: there’s no free lunch – molto probabilmente, non esiste una soluzione generale al problema, ma andranno studiate soluzioni diverse, specializzate e declinate nei diversi contesti applicativi, nei quali gli esperti di dominio potranno dialogare e istruire l’IA per renderla più robusta, affidabile e allineata ai principi della nostra società. Parafrasando il celebre campione di scacchi Garry Kasparov, più che immaginare un futuro in cui l’IA sarà completamente autonoma, possiamo più ragionevolmente aspettarci di avere una IA al servizio degli umani. Più che “intelligenza artificiale”, quindi, si parlerà sempre di IA ma intendendo una “intelligenza aumentata” e non artificiale.












